
Google Cloud launches Agentic Data Cloud for AI agents
Thu, 23rd Apr 2026
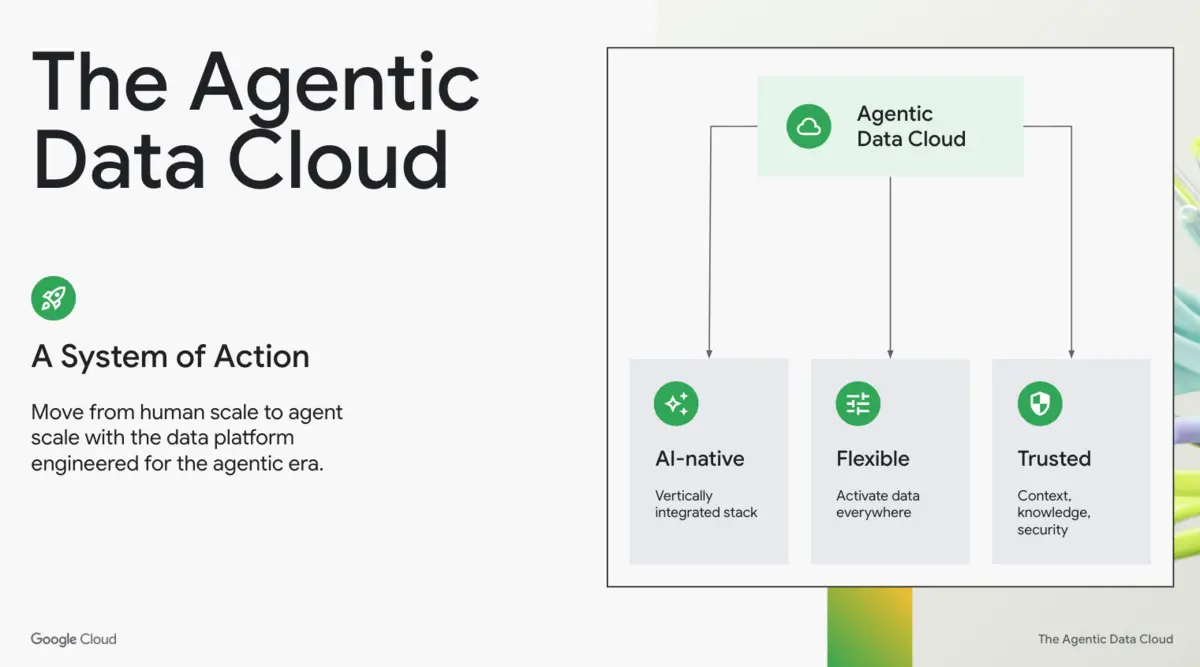
Google Cloud has introduced what it calls an Agentic Data Cloud, centred on new data and analytics tools for autonomous software agents.
The update aims to reshape its data platform into what it describes as a "System of Action", spanning data cataloguing, analytics, lakehouse infrastructure and developer tooling.
At the centre of the announcement is an update to Dataplex Universal Catalog, now expanded into a Knowledge Catalog. The system is designed to give software agents business context across data assets, applications and documents, allowing them to retrieve information and act within existing access controls.
The Knowledge Catalog aggregates metadata and business meaning from Google services and partner platforms, including Palantir, Salesforce Data360, SAP, ServiceNow and Workday, in preview. It also uses activity data and analysis of structured and unstructured files to enrich that context over time. Search combines semantic and lexical matching with security-aware access controls.
The catalog now supports Google Cloud's Deep Research Agent, in preview within Gemini Enterprise. The tool is designed to carry out multi-step reasoning across Google Cloud data platforms, internal documents and web assets.
Developer tools
Google Cloud also unveiled the Google Cloud Data Agent Kit in preview, a set of tools and extensions for developers and data teams working in environments such as VS Code, Gemini CLI, Codex and Claude Code. The kit is intended to let practitioners orchestrate data tasks from familiar tools rather than move to a separate interface.
The suite includes the Data Engineering Agent and Data Science Agent, both generally available, and a Database Observability Agent in preview. These tools are designed to support pipeline creation, model development and database diagnosis.
Google Cloud is also adopting the Model Context Protocol across core data services including BigQuery, AlloyDB and Cloud SQL, with Spanner and Looker support in preview. The protocol is intended to let agents discover and use data assets while operating under existing identity, network and residency controls.
For business users, Conversational Analytics is now supported across BigQuery and Looker, and is in preview or rolling out across Cloud SQL, Spanner and AlloyDB. The feature is designed to let staff query live data through natural-language interfaces.
Cross-cloud push
A second part of the launch focuses on cross-cloud access. Google Cloud is integrating Cross-Cloud Interconnect into its data plane and using the Apache Iceberg REST Catalog to support access to data held across multiple cloud environments.
It also announced bi-directional federation in preview, allowing engines to read directly from Databricks Unity Catalog on Amazon S3, Snowflake Polaris and AWS Glue Data Catalog on Amazon S3. Enhanced Lakehouse Governance, also in preview, is intended to apply security and access rules across that environment.
Another addition is Spanner Omni, in preview, which will allow the Spanner database engine to run across clouds, on-premises and in local environments. Google Cloud also introduced lakehouse federation for AlloyDB, in preview, aimed at reducing the need for extract, transform and load pipelines by synchronising operational and analytical data more directly.
Customer use
Google Cloud tied the rollout to customer examples across telecoms, financial services and travel. Vodafone has launched hundreds of software agents to support customer service operations, while American Express is moving a core on-premises data warehouse and hundreds of production applications to BigQuery.
Virgin Voyages is using more than 1,000 specialised AI agents, according to Google Cloud. One of them has reduced the time needed for mass itinerary rebooking from six hours to 11 minutes.
The launch also included infrastructure and performance updates. According to Google Cloud, Lightning Engine for Apache Spark delivers up to twice the price-performance of a proprietary alternative, while Managed Lustre offers up to 10 terabytes per second of throughput.
Bigtable now includes an in-memory tier for sub-millisecond read latency. BigQuery fluid scaling can also lower costs by up to 34% on average for autoscaling workloads, according to the company.
"Companies are shifting from gen AI that simply answers questions to autonomous agents that perceive, reason, and act on their behalf," said Andi Gutmans, Vice President and General Manager, Data Cloud, Google Cloud, and Yasmeen Ahmad, Managing Director, Data Cloud, Google Cloud.
